
First of all, some shader tipps:
1.) When possible, don’t use loops/ifs (or anything else that requires branching). The GPU is optimized the most for a linear flow of execution, meaning no jumps (other than from intstruction to instruction  ). Modern desktop GPUs may be better at handling branches, but embedded and especially old GPUs are not.
). Modern desktop GPUs may be better at handling branches, but embedded and especially old GPUs are not.
2.) Reduce texture cache misses. The memory latency on GPUs is usually high. This means that fetching memory off chip, uses a quite significant amount of time. Although many GPUs try to hide this by doing other work while waiting for the texture data. To reduce off chip texture memory fetches, the GPU uses a texture data cache. When a cache miss happens (a texel is fetched that is not in the cache), the current gpu thread stalls and waits for the data to be read from memory.
One common root of cache misses are dependent texture reads/fetches. These happen when the texture coordinate (the second value passed to the texture2D function) is computed at pixel-shader time. Like in the following example:
varying vec2 texCoord;
uniform float value;
void main() {
gl_FragColor = texture2D(tex, vec2(texCoord.x - value * 0.25, texCoord.y - value * 0.25));
}
Here the texture coordinate is computed at every pixel shader iteration. This is a dependent-texture-read. An independent-texture-read (don’t know if that’s really how it’s called, but I’ll call it that way for now ) looks like this:
varying vec2 texCoord;
void main() {
gl_FragColor = texture2D(tex, texCoord);
}
The texture coordinate value passed to the texture2D function comes straight from a varying.
But since some calculation needs to be done on the texture coordinate the above can’t be done by just removing the calculations.
This: texCoord.x - value * 0.25 forms a linear (mathematical) function. With linear functions, the following statement can be made.
f(x) = x - value * 0.25
lerp(f(x1), f(x2), t) = f(lerp(x1, x2, t))
If you already know or don’t care you can skip the proof.
f(x) = x - v * c
lerp(x,y,t) = (y - x) * t + x
f(lerp(x1, x2, t)) = ((x2 - x1) * t + x1) - v * c
= (x2 - x1) * t + x1 - v * c
lerp(f(x1), f(x2), t) = (f(x2) - f(x1)) * t + f(x1)
= ((x2 - v * c) - (x1 - v * c)) * t + (x1 - v * c)
= (x2 - v * c - x1 + v * c) * t + x1 - v * c
= (x2 - x1 - v * c + v * c) * t + x1 - v * c
= (x2 - x1) * t + x1 - v * c
What the above states, is that it doesn’t matter for the result if you either lineary interpolate between the results of f(x1) and f(x2), or interpolate between x1 and x2 and then use it as input to the linear function. Since varying are lineary interpolated across the primitive, this behaviour can be exploited to move the calculations to the vertex shader.
(NOTE: Varyings are actually not lineary interpolated across the primitive in general, but rather interpolated with perspective correction. But since we are drawing a non-perspective rectangle (gl_Position.w = 1.0), the interpolation remains linear.)
Now about the blur. The blur used in the video you provided seems to be a gaussian type of blur. One thing that is noticeable, is that there is almost no more detail left after blurring. This probably is the result of a very large blur radius or a heavily downscaled source image with a smaller blur radius.
Gaussian blur filters are usually very heavy (atleast on mobile), so they are avoided when possible. One trick is to downscale the source image in multiple passes to a size like 16px or so. Then draw it at full screen resolution with linear sampling enabled. This should give a reasonably fast blur effect.
 But, is there any working in real life code sample?
But, is there any working in real life code sample?
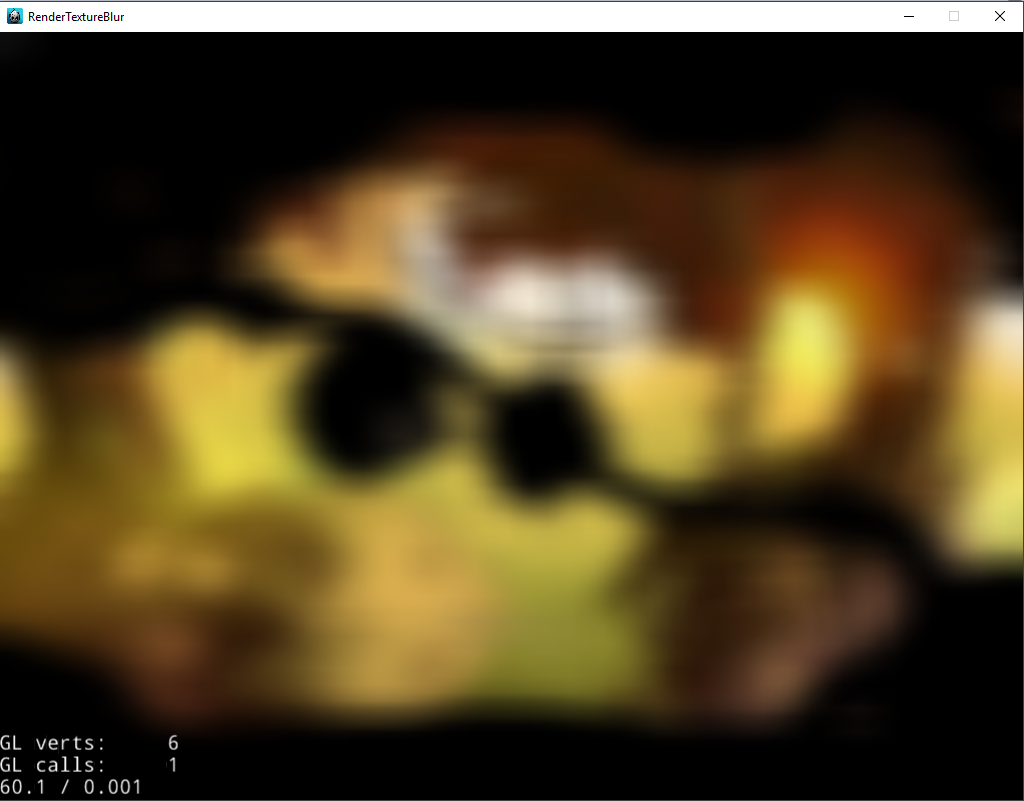





 For static downsampled image it works very fast and looks perfect!
For static downsampled image it works very fast and looks perfect!

